图片展示需要 BGR 模式的三维向量,图片的编码是把 BGR 图片编码成文件能存储的格式,解码则反之。目前常见的编码为 JPG、PNG、GIF 等,新兴的如 WEBP、 HEIC 等。
BMP
从简单入手,BMP 是最简单的编码方式,甚至数十行代码就能完成编码和解码简单的程序。 BMP 由文件头和位图信息头组成:
import struct
import numpy as np
BITMAP_FILE_HEADER_FMT = '<2sI4xI'
BITMAP_FILE_HEADER_SIZE = struct.calcsize(BITMAP_FILE_HEADER_FMT)
BITMAP_INFO_FMT = '<I2i2H6I'
BITMAP_INFO_SIZE = struct.calcsize(BITMAP_INFO_FMT)
class BmpHeader:
def __init__(self):
self.bf_type = None
self.bf_size = 0
self.bf_off_bits = 0
self.bi_size = 0
self.bi_width = 0
self.bi_height = 0
self.bi_planes = 1 # 颜色平面数
self.bi_bit_count = 0
self.bi_compression = 0
self.bi_size_image = 0
self.bi_x_pels_per_meter = 0
self.bi_y_pels_per_meter = 0
self.bi_clr_used = 0
self.bi_clr_important = 0
class BmpDecoder:
def __init__(self, data):
self.__header = BmpHeader()
self.__data = data
def read_header(self):
if self.__header.bf_type is not None:
return self.__header
# BMP 信息头
self.__header.bf_type, self.__header.bf_size,\
self.__header.bf_off_bits = struct.unpack_from(BITMAP_FILE_HEADER_FMT, self.__data)
if self.__header.bf_type != b'BM':
return None
# 位图信息头
self.__header.bi_size, self.__header.bi_width, self.__header.bi_height, self.__header.bi_planes,\
self.__header.bi_bit_count, self.__header.bi_compression, self.__header.bi_size_image,\
self.__header.bi_x_pels_per_meter, self.__header.bi_y_pels_per_meter, self.__header.bi_clr_used,\
self.__header.bi_clr_important = struct.unpack_from(BITMAP_INFO_FMT, self.__data, BITMAP_FILE_HEADER_SIZE)
return self.__header
def read_data(self):
header = self.read_header()
if header is None:
return None
# 目前只写了解析常见的 24 位或 32 位位图
if header.bi_bit_count != 24 and header.bi_bit_count != 32:
return None
# 目前只写了 RGB 模式
if header.bi_compression != 0:
return None
offset = header.bf_off_bits
channel = int(header.bi_bit_count / 8)
img = np.zeros([header.bi_height, header.bi_width, channel], np.uint8)
y_axis = range(header.bi_height - 1, -1, -1) if header.bi_height > 0 else range(0, header.bi_height)
for y in y_axis:
for x in range(0, header.bi_width):
plex = np.array(struct.unpack_from('<' + str(channel) + 'B', self.__data, offset), np.int8)
img[y][x] = plex
offset += channel
return img
class BmpEncoder:
def __init__(self, img):
self.__img = img
def write_data(self):
image_height, image_width, channel = self.__img.shape
# 只支持RGB或者RGBA图片
if channel != 3 and channel != 4:
return False
header = BmpHeader()
header.bf_type = b'BM'
header.bi_bit_count = channel * 8
header.bi_width = image_width
header.bi_height = image_height
header.bi_size = BITMAP_INFO_SIZE
header.bf_off_bits = header.bi_size + BITMAP_FILE_HEADER_SIZE
header.bf_size = header.bf_off_bits + image_height * image_width * channel
buffer = bytearray(header.bf_size)
# bmp信息头
struct.pack_into(BITMAP_FILE_HEADER_FMT, buffer, 0, header.bf_type, header.bf_size, header.bf_off_bits)
# 位图信息头
struct.pack_into(BITMAP_INFO_FMT, buffer, BITMAP_FILE_HEADER_SIZE, header.bi_size, header.bi_width, header.bi_height,
header.bi_planes, header.bi_bit_count, header.bi_compression, header.bi_size_image,
header.bi_x_pels_per_meter, header.bi_y_pels_per_meter, header.bi_clr_used,
header.bi_clr_important)
# 位图,一般都是纵坐标倒序模式
offset = header.bf_off_bits
for y in range(header.bi_height - 1, -1, -1):
for x in range(header.bi_width):
struct.pack_into('<' + str(channel) + 'B', buffer, offset, *self.__img[y][x])
offset += channel
return buffer
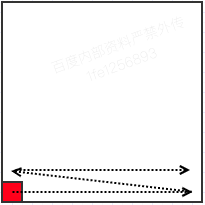
从上面的代码我们可以感受到,图片编码其实就类似于我们把内存中的结构体序列化方便我们传输一样,其实是为了更好地传输图片。除此之外,需要关注的一个点是, BMP 图片的纵坐标是反过来的,如下图所示:
JPEG
下面进入本文重点。 JPEG 是一种编码压缩方法,真正描述图片如何存储的是 JFIF(JPEG File Interchange Format),但是普通交流中往往使用"JPEG文件" 这种叫法。由于精力有限,只尝试了JPEG解码的步骤。
背景知识
DCT
离散余弦变换(Discrete Cosine Transform),把信号从空域转换成频域,且具有较好的能量聚集。变换公式如下:
DCT:$ F(u ,v) = \alpha(u)\alpha(v)\sum^{M-1}_{x=0}\sum^{N-1} f(x,y)cos(\frac{(2x+1)u\pi}{2M})cos(\frac{(2y+1)v\pi}{2N}). $
其中 $ \alpha(u) = \begin{cases} \sqrt{\frac{1}{N}},\ u = 0 \\\sqrt{\frac{2}{N}},\ u\ne0\end{cases} $。
IDCT:$ f(x, y) = \alpha(u)\alpha(v)\sum^{M-1}_{u=0}\sum^{N-1} F(u, v)cos(\frac{(2x+1)u\pi}{2M})cos(\frac{(2y+1)v\pi}{2N}). $
其中 $ \alpha(u) = \begin{cases} \sqrt{\frac{1}{N}},\ u = 0 \\\sqrt{\frac{2}{N}},\ u\ne0\end{cases} $。
可以阅读 Matlab 的帮助文档 离散余弦变换- MATLAB & Simulink- MathWorks 中国 ,或者一篇博客 离散余弦变换(DCT)的来龙去脉_独孤呆博的博客-CSDN博客_二维离散余弦变换 了解更多。
哈夫曼编码
根据符号出现概率,使用较短的编码更频繁出现的符号。更详细的可以阅读 详细图解哈夫曼Huffman编码树_无鞋童鞋的博客-CSDN博客_huffman编码树。
色差信号
使用亮度和蓝色、红色的浓度偏移量描述图像信号的色彩空间,和RGB转换公式可阅读 YCbCr - Wikipedia。 使用 YCbCr 是因为,人眼对于亮度对比的感知能力比色彩的感知能力要强,把亮度分量分离出来后,可以有针对性地使用不同的量化表、采样因子来达到不同的压缩率, 且人眼感知不强。
读取JPEG文件Header
JPEG 文件在制定规范时,定义文件是由 marker 和 segment 组成。marker 都是以 0xff 开头,以非 0x00 结束。对应常用 marker 如下:
| marker | value | description |
|---|---|---|
| SOI | 0xFFD8 |
图像开始(Start Of Scan) |
| APP0 | 0xFFE0 |
存储图像参数 |
| APP1 | 0xFFE2 |
|
| APP12 | 0xFFEC |
图片质量等信息 |
| APP13 | 0xFFED |
Phptoshop 存储的信息 Photoshop Tags |
| SOF0 | 0xFFC0 |
Start Of Frame,SOF0 是 baseline DCT |
| SOF2 | 0xFFC2 |
Start Of Frame,SOF2 是 progressive DCT |
| DHT | 0xFFC4 |
Define Huffman Table,定义哈夫曼编码表,可以有多个,具体重建哈夫曼树方法见下 |
| DQT | 0xFFDB |
Define Quantization Table,定义量化表,可以有多个。量化表能影响图片的压缩质量 |
| DRI | 0xFFDD |
Define Restart Interval,重置 DC 信号的间隔(每解码指定次 MCU 就重置 DC 信号) |
| SOS | 0xFFDA |
Start Of Scan |
| image data | 如果有 0xFF 的数据,会使用 0xFF00 表示,解码的时候需要注意 |
|
| EOI | 0xFFD9 |
End Of Image |
更多 marker 可以参考 exiftool 的文档 JPEG Tags
APP0
| field | size(bytes) | description |
|---|---|---|
| 长度 | 2 | 包括这个字段为首的整个 segment 长度 |
| 标识符 | 5 | 图片编码方式,JFIF\0 或者 JFXX\0 等,下面的字段均以 JFIF 为示例 |
JFIF 格式会接着有下列这些字段
| field | size(bytes) | description |
|---|---|---|
| JFIF 版本 | 2 | 第一个字节为主版本,第二个字节为次要版本(01 02表示1.02) |
| 密度单位 | 1 | 下列像素密度字段的单位:00:无单位;width:height 像素宽高比 = Xdensity:Ydensity;01:每英寸像素(2.54厘米);02:每英寸像素。 |
| x方向密度 | 2 | 水平像素密度。不得为 0。 |
| y方向密度 | 2 | 垂直像素密度。不得为 0。 |
| 缩略图宽度 | 1 | 嵌入的 RGB 缩略图的水平像素数。可以为 0。 |
| 缩略图高度 | 1 | 嵌入的 RGB 缩略图的垂直像素数。可以为 0。 |
| 缩略图数据 | 3n | 未压缩的 24 位 RGB(每个颜色通道 8 位)光栅缩略图数据,顺序为 R0、G0、B0、...Rn、Gn、Bn;其中 n = Xthumbnail × Ythumbnail。 |
APP12
| field | size(bytes) | description |
|---|---|---|
| 长度 | 2 | 包括这个字段为首的整个 segment 长度 |
| 标识符 | "Ducky"等 |
Ducky 类型接下来会是这些
| field | size(bytes) | description |
|---|---|---|
| tag | 2 | 0x0001:压缩质量,uint32;0x0002:评论,string;0x0003:版权,string |
| 长度 | 2 | 接下来的内容长度 |
| 内容 |
SOF0
| field | size(bytes) | description |
|---|---|---|
| 长度 | 2 | 包括这个字段为首的整个 segment 长度 |
| 精度 | 1 | 每像素数据位数,一般为 8bit |
| 高度 | 2 | 图像高度 |
| 宽度 | 2 | 图像宽度 |
| 颜色分量数 | 1 | 01:灰度图;03:YCbCr 图,一般为这个;04:CMYK |
| 颜色分量信息 | 三色分量数*3 | 3 字节分别为:颜色分量 ID;水平和垂直采样因子,水平为高 4 位,垂直为低 4 位;使用的量化表 ID |
DHT
| field | size(bytes) | description |
|---|---|---|
| 长度 | 2 | 包括这个字段为首的整个 segment 长度 |
| 表类型和表ID | 1 | 高 4 位为表类型,其中:0 位 DC,1为AC;低 4 位为哈夫曼表 ID。 |
| 不同长度码字数量 | 16 | 码字长度为 1-16 位的时候各位的数量,详见下 |
| 各个码字对应的内容 | 用于构建哈夫曼树 |
举例,若不同码字长度的记录如:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 5 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
各个长度码字对应内容如下:
| bit_length | code | symbol |
|---|---|---|
| 2 | 00 | 0 |
| 3 | 010 | 1 |
| 3 | 011 | 2 |
| 3 | 100 | 3 |
| 3 | 101 | 4 |
| 3 | 110 | 5 |
| 4 | 1110 | 6 |
| 5 | 11110 | 7 |
| 6 | 111110 | 8 |
| 7 | 1111110 | 9 |
| 8 | 11111110 | 10 |
| 9 | 111111110 | 11 |
DQT
| field | size(bytes) | description |
|---|---|---|
| 长度 | 2 | 包括这个字段为首的整个 segment 长度 |
| 精度和表ID | 1 | 高 4 位为精度,0为 8 位,1 为 16 位;低 4 位未量化表 ID。 |
| 低4位未量化表ID。 | 64*(精度) | 8x8 的量化表数据 |
DRI
| field | size(bytes) | description |
|---|---|---|
| 长度 | 2 | 包括这个字段为首的整个 segment 长度 |
| 重置DC间隔 | 2 | 每隔x个MCU就重置一次所有DC信号 prev 的值,此时读取的文件流会有 RST 标记,这个 RST 标记会随着重启次数而递增,如第一次重启标记为 0xD0,第二次则为 0xD1 直到 0xD7 后会再回到 0xD0 如此循环 |
一个解码jpeg文件的示例
初始化
获取整个图片 component 的数量,图片宽高,构建量化表、哈夫曼表,获取到各个 component 对应哈夫曼表 ID、量化表、垂直和水平采样因子。
采样引子
因为图片保存时候是按照 YCbCr 保存的,而人眼对亮度比较敏感,对于色度不太敏感,因此可以对色度浓度更小的抽样,亮度按照原样抽样。JPEG 在解码时候一个 解码单元为一个 MCU(Minimum Coded Unit)。一个 MCU 的大小取决于各个 component 的采样因子。MCU 的宽度为 max(各个componet的水平采样因子)*8, 高度为 max(各个component的垂直采样因子) * 8。常见的,如Y的采样因子为 2x2,Cb、Cr 的采样因子为 1x1,则一个 MCU 内数据的分布则是 Y1、Y2、Y3、 Y4、Cb1、Cr1,6 小块,每小块是 8x8 像素的编码单元,整个 MCU 大小为 16x16,这个MCU的各个数据分布如下:
| Y1Cb1Cr1 | Y2 |
|---|---|
| Y3 | Y4 |
如果一个Y、Cb、Cr的采样因子均为1x1,则整个MCU大小为8x8。
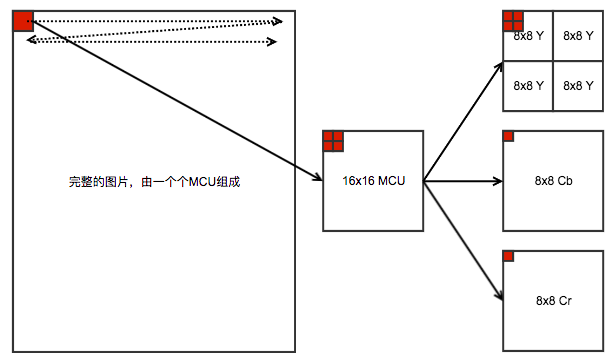
采样因子比例常见有 4:2:2, 4:1:1, 4:4:4。
哈夫曼表
哈夫曼表区分了之流和交流表,一般有 4 个哈夫曼表,分别是亮度 DC,亮度 AC,色度 DC,色度 AC 表。哈夫曼表用于压缩最终的图像编码。如示例的图片的亮度 DC 表如下:
| bit_length | code | symbol |
|---|---|---|
| 2 | 00 | 0 |
| 3 | 010 | 1 |
| 3 | 011 | 2 |
| 3 | 100 | 3 |
| 3 | 101 | 4 |
| 3 | 110 | 5 |
| 4 | 1110 | 6 |
| 5 | 11110 | 7 |
| 6 | 111110 | 8 |
| 7 | 1111110 | 9 |
| 8 | 11111110 | 10 |
| 9 | 111111110 | 11 |
量化表
量化表一般为 2 个,亮度 1 个,色度 1 个。量化表用于编码时候把 DCT 转换后的矩阵除以这个量化表,使得高频部分尽量约等于 0,这样在最终编码的时候四舍 五入能把大部分高频部分都压缩成 0,乐观情况下只有 DC,AC 全为 0,只需要 2bit 就能表示剩余 63 个AC信号了!例如示例的 DC 量化表如下:
| 16 | 11 | 12 | 14 | 12 | 10 | 16 | 14 |
|---|---|---|---|---|---|---|---|
| 12 | 14 | 18 | 17 | 16 | 19 | 24 | 40 |
| 26 | 24 | 22 | 22 | 24 | 49 | 35 | 37 |
| 29 | 40 | 58 | 51 | 61 | 60 | 57 | 51 |
| 56 | 55 | 64 | 72 | 92 | 78 | 64 | 68 |
| 87 | 69 | 55 | 56 | 80 | 109 | 81 | 87 |
| 95 | 98 | 103 | 104 | 103 | 62 | 77 | 113 |
| 121 | 112 | 100 | 120 | 92 | 101 | 103 | 99 |
解码一个 MCU
解码 MCU 时,需要读取多个 8x8 的block。每个 block 均由 1 个DC信号和 63 个 AC 信号组成。解码时先读取 DC 信号,再读取 AC 信号。我们捋一下, 对于 baseline DCT 编码的图片,目前我们各个颜色分量对应的 ht,qt 关系如下:
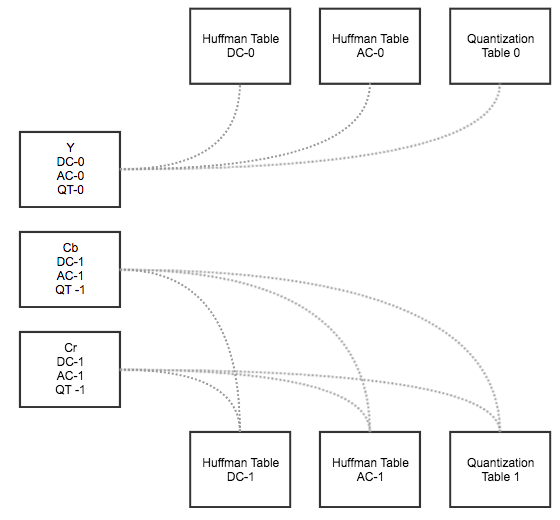
也就是说,一个颜色分量有 1 个直流 ht,1 个交流 ht,1 个量化表。
解码一个block
解码DC信号
由于相邻的 block 之间 DC 信号的差异很小,DC 信号使用 DPCM(Differential Pulse Code Modulation)编码。读取时通过对应哈夫曼表找到对应代表符 号,然后读取对应位数的数值,然后进行 DPCM 解码。例如例子中,第一个 MCU 的亮度 component 的 4 个 block 读取出来的值分别为 -37,1,-1,-1, 则最终 4 个 block 的DC信号分别为 -37,-36,-37,-38。每个 component 之间的 DCPM 编码是独立的。
解码AC信号
AC 信号的编码使用 RLE(Run Length Encoding) 编码。读取时通过对应哈夫曼表找到对应符号,对应符号的高 4 位未接下来有几个连续的 0,低 4 位为这些
0 后面跟着的位数,然后读取对应位数的数值。特别地,当读取到 0x00 时,代表接下来这个 block 所有数字为 0,当读取的值为 0xf0 时,代表接下来有
16 个 0。
zig-zag解码
8x8 矩阵在编码时并不是按顺序读取,因此解码的时候也需要还原,其读取顺序如下:
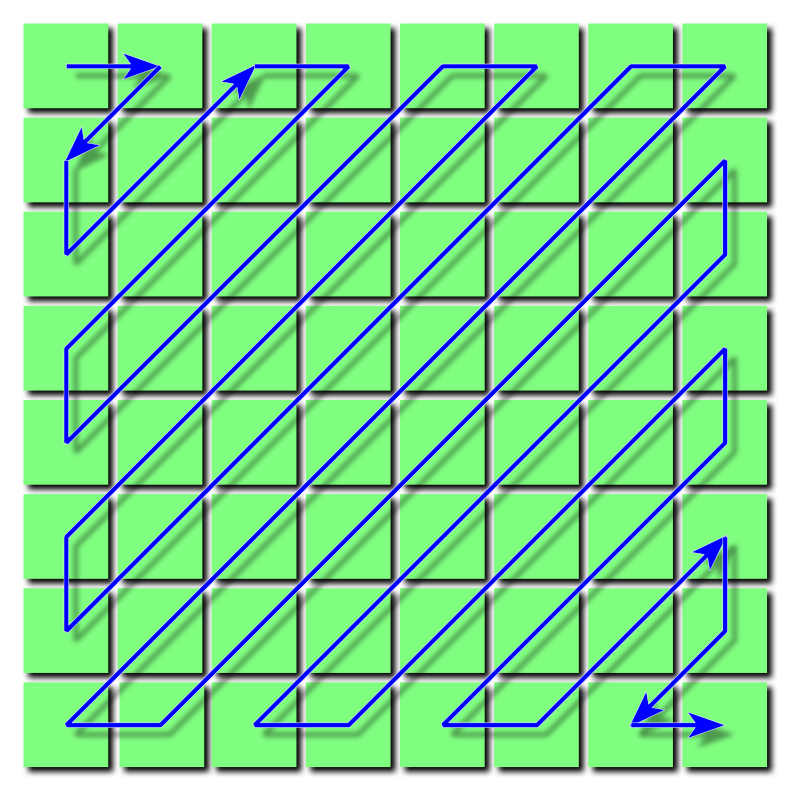
zig-zag 编码原因是,大部分能量(振幅)都集中在左上角(低频区域),为了编码 AC 信号时能更高的连续性,AC 信号是 RLE 编码的,因此同一个数值连续数量越多 压缩率越大。高频数据往往为 0,而 AC 信号解码时遇到 0 则表示后续全部为 0。
反量化
经过zigzag解码后,此时block的矩阵长这样:
| -37 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
需要和量化表点乘一下,最终结果长这样:
| -592 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
只有 -592 一个直流信号,可见这个 8x8 的 block 在 DCT 变换前,64 个像素颜色一样(也可能存在一点点差别,但是在量化时候四舍五入走了)。
IDCT
把 block 从频域转换为空域,计算时往往使用矩阵叉乘加快速度。结果补码转成原码,并把符号位去掉,最终结果:
| 54 | 54 | 54 | 54 | 54 | 54 | 54 | 54 |
|---|---|---|---|---|---|---|---|
| 54 | 54 | 54 | 54 | 54 | 54 | 54 | 54 |
| 54 | 54 | 54 | 54 | 54 | 54 | 54 | 54 |
| 54 | 54 | 54 | 54 | 54 | 54 | 54 | 54 |
| 54 | 54 | 54 | 54 | 54 | 54 | 54 | 54 |
| 54 | 54 | 54 | 54 | 54 | 54 | 54 | 54 |
| 54 | 54 | 54 | 54 | 54 | 54 | 54 | 54 |
| 54 | 54 | 54 | 54 | 54 | 54 | 54 | 54 |
解码JPEG文件示例
import abc
import itertools
import struct
import sys
import typing
import cv2
import numpy as np
from scipy import fft, ndimage
FRAME_SOF0 = b'\xc0' # Start Of Frame N
FRAME_SOF1 = b'\xc1' # N indicates which compression process
FRAME_SOF2 = b'\xc2' # Only SOF0-SOF2 are now in common use
FRAME_SOF3 = b'\xc3'
FRAME_SOF5 = b'\xc5' # NB: codes C4 and CC are NOT SOF markers
FRAME_SOF6 = b'\xc6'
FRAME_SOF7 = b'\xc7'
FRAME_SOF8 = b'\xc8'
FRAME_SOF9 = b'\xc9'
FRAME_SOF10 = b'\xca'
FRAME_SOF11 = b'\xcb'
FRAME_SOF13 = b'\xcd'
FRAME_SOF14 = b'\xce'
FRAME_SOF15 = b'\xcf'
FRAME_SOI = b'\xd8'
FRAME_EOI = b'\xd9' # End Of Image (end of datastream)
FRAME_SOS = b'\xda' # Start Of Scan (begins compressed data)
FRAME_APP0 = b'\xe0'
FRAME_APP1 = b'\xe1'
FRAME_APP2 = b'\xe2'
FRAME_APP3 = b'\xe3'
FRAME_APP4 = b'\xe4'
FRAME_APP5 = b'\xe5'
FRAME_APP6 = b'\xe6'
FRAME_APP7 = b'\xe7'
FRAME_APP8 = b'\xe8'
FRAME_APP9 = b'\xe9'
FRAME_APP10 = b'\xea'
FRAME_APP11 = b'\xeb'
FRAME_APP12 = b'\xec'
FRAME_APP13 = b'\xed'
FRAME_APP14 = b'\xee'
FRAME_APP15 = b'\xef'
FRAME_DQT = b'\xdb'
FRAME_DRI = b'\xdd'
FRAME_DHT = b'\xc4'
ZIGZAGINVERSE = np.array([[0, 1, 5, 6, 14, 15, 27, 28],
[2, 4, 7, 13, 16, 26, 29, 42],
[3, 8, 12, 17, 25, 30, 41, 43],
[9, 11, 18, 24, 31, 40, 44, 53],
[10, 19, 23, 32, 39, 45, 52, 54],
[20, 22, 33, 38, 46, 51, 55, 60],
[21, 34, 37, 47, 50, 56, 59, 61],
[35, 36, 48, 49, 57, 58, 62, 63]])
ZIGZAGFLATINVERSE = ZIGZAGINVERSE.flatten()
ZIGZAGFLAT = np.argsort(ZIGZAGFLATINVERSE)
def zigzag_single(block):
return block.flatten()[ZIGZAGFLAT].reshape([8, 8])
def inverse_zigzag_single(array):
return array.flatten()[ZIGZAGFLATINVERSE].reshape([8, 8])
def decode_number(bit_length, bits):
"""
补码转原码
:param bit_length:
:param bits:
:return:
"""
b = 2 ** (bit_length - 1)
if bits >= b:
return bits
else:
return bits - (2 * b - 1)
class BitStream:
def __init__(self, data):
self.data = data
self.pos = 0
def get_bit(self):
byte = self.data[self.pos >> 3]
offset = 7 - (self.pos & 0x07)
self.pos += 1
return (byte >> offset) & 0x01
def get_bits(self, n):
val = 0
for _ in range(n):
val = val << 1 | self.get_bit()
return val
class HuffmanCodec:
def __init__(self):
self._root = []
self._symbol = []
def _travel_root(self, root, code, bit_length, result):
if len(root) == 0:
return
if isinstance(root[0], list):
self._travel_root(root[0], code << 1, bit_length + 1, result)
else:
result.append((code << 1, bit_length, root[0]))
if len(root) == 2:
if isinstance(root[1], list):
self._travel_root(root[1], code << 1 | 1, bit_length + 1, result)
else:
result.append((code << 1 | 1, bit_length, root[1]))
def print_code_table(self, out=sys.stdout):
code = 0
result = []
self._travel_root(self._root, code, 1, result)
columns = list(zip(*itertools.chain(
[('Bits', 'Code', 'Value', 'Symbol')],
((str(v[1]), bin(v[0])[2:].rjust(v[1], '0'), str(v[0]), repr(v[2])) for v in result)
)))
widths = tuple(max(len(s) for s in col) for col in columns)
template = '{0:>%d} {1:%d} {2:>%d} {3}\n' % widths[:3]
for row in zip(*columns):
out.write(template.format(*row))
def _add_symbol(self, root, symbol, pos):
if isinstance(root, list):
if pos == 0:
if len(root) < 2:
root.append(symbol)
return True
return False
for i in [0, 1]:
if len(root) == i:
root.append([])
if self._add_symbol(root[i], symbol, pos - 1):
return True
return False
def build_from_bits(self, bits_length_seq, symbol_seq):
self._symbol = symbol_seq
symbol_index = 0 # 当前使用到symbol列表的下标
for i, count in enumerate(bits_length_seq):
for j in range(count):
self._add_symbol(self._root, symbol_seq[symbol_index], i)
symbol_index += 1
def _find(self, bit_stream: BitStream):
node = self._root
while isinstance(node, list):
node = node[bit_stream.get_bit()]
return node
def get_symbol(self, bit_stream) -> int:
while True:
res = self._find(bit_stream)
if bit_stream == 0:
return 0
elif res != -1:
return res
class JpegMarker:
identify = ''
def __init__(self, marker):
self.__marker = marker
def marker(self):
return self.__marker
@abc.abstractmethod
def encode(self):
pass
@abc.abstractmethod
def decode(self, data):
pass
class JpegApp0Marker(JpegMarker):
def __init__(self, marker):
super().__init__(marker)
self.__main_version = 0
self.__sub_version = 0
self.__density = 0
self.__x_density = 0
self.__y_density = 0
self.__x_thumbnail = 0
self.__y_thumbnail = 0
def encode(self):
pass
def decode(self, data):
offset = 0
while data[offset] != 0 and offset < len(data) - 1:
self.identify += chr(data[offset])
offset += 1
self.__main_version, self.__sub_version, self.__density, self.__x_density, self.__y_density, \
self.__x_thumbnail, self.__y_thumbnail = struct.unpack_from('>3B2H2B', data, offset + 1)
class JpegApp1Marker(JpegMarker):
def encode(self):
pass
def decode(self, data):
pass
class JpegApp12Marker(JpegMarker):
def __init__(self, marker):
super().__init__(marker)
self.quality = None
self.comment = None
self.copyright = None
def encode(self):
pass
def decode(self, data):
data_size = len(data)
tag_name = ''
offset = 0
while data[offset] != 0 and offset < data_size:
tag_name += chr(data[offset])
offset += 1
if tag_name == 'Ducky':
while offset < data_size:
tag, = struct.unpack_from('2s', data, offset)
if tag == b'\x00\x00':
break
offset += 2
value_size, = struct.unpack_from('>H', data, offset)
offset += 2
if tag == b'\x00\x01':
# quality
self.quality, = struct.unpack_from('>I', data, offset)
if tag == 2:
# comment
self.comment, = struct.unpack_from(str(value_size) + 's', data, offset)
if tag == 3:
# copyright
self.copyright, = struct.unpack_from(str(value_size) + 's', data, offset)
offset += value_size
class JpegApp13Marker(JpegMarker):
def encode(self):
pass
def decode(self, data):
print(data)
class JpegApp14Marker(JpegMarker):
def __init__(self, marker):
super().__init__(marker)
self.dct_encode_version = None
self.flags_0 = None
self.flags_1 = None
self.color_transform = None
def encode(self):
pass
def decode(self, data):
tag_name, version, flag0, flag1, color = struct.unpack('>5sxB2HB', data)
if tag_name == b'Adobe':
self.dct_encode_version = version
self.flags_0 = flag0
self.flags_1 = flag1
self.color_transform = color
class JpegDQTMarker(JpegMarker):
def __init__(self, marker):
super().__init__(marker)
self.table_id = None
self.data_matrix = None
def encode(self):
pass
def decode(self, data):
tmp, = struct.unpack_from('B', data)
precision = (tmp & 0xF0) >> 4 # 0: 8位, 1: 16位
self.table_id = tmp & 0x0F
data = struct.unpack_from(str(64 * (precision + 1)) + 'B', data, 1)
self.data_matrix = np.array(data, np.uint8).reshape([8 * (precision + 1), 8 * (precision + 1)])
class JpegSof0Marker(JpegMarker):
def __init__(self, marker):
super().__init__(marker)
self.precision = 0
self.width = 0
self.height = 0
self.channel_count = 0
self.channel_info = {}
def encode(self):
pass
def decode(self, data):
self.precision, self.width, self.height, self.channel_count = struct.unpack_from('>B2HB', data)
offset = 6
for i in range(self.channel_count):
channel_id, sampling_factor, dqt_id = struct.unpack_from('>3B', data, offset)
self.channel_info[channel_id] = {
'horizontal_factor': (sampling_factor & 0xF0) >> 4,
'vertical_factor': sampling_factor & 0x0F,
'dqt_id': dqt_id
}
offset += 3
class JpegDhtMarker(JpegMarker):
def __init__(self, marker):
super().__init__(marker)
self.table_id = 0
self.type = None
self.bits_length_seq = None
self.symbol_seq = None
def encode(self):
pass
def decode(self, data):
tmp, = struct.unpack_from('B', data)
self.type = (tmp & 0xF0) >> 4
self.table_id = tmp & 0x0F
self.bits_length_seq = struct.unpack_from('16B', data, 1)
self.symbol_seq = struct.unpack_from(str(sum(self.bits_length_seq)) + 'B', data, 17)
class JpegDriMarker(JpegMarker):
def __init__(self, marker):
super().__init__(marker)
self.restart_interval = 0
def encode(self):
pass
def decode(self, data):
self.restart_interval, = struct.unpack_from('>H', data)
class JpegImageMarker(JpegMarker):
def __init__(self, marker):
super().__init__(marker)
self.channel_count = None # 1灰度图 3YCrCb 4 CMYK
self.huffman_map = {}
self.image_data = None
def encode(self):
pass
def decode(self, data):
info_size, = struct.unpack_from('>H', data)
self.image_data = self._remove_ff00(data[info_size:])
self.channel_count, = struct.unpack_from('>B', data, 2)
offset = 3
for i in range(0, self.channel_count):
channel_id, huffman_table = struct.unpack_from('>2B', data, offset)
offset += 2
self.huffman_map[channel_id] = {
'AC': (huffman_table & 0xF0) >> 4,
'DC': huffman_table & 0x0F,
}
@staticmethod
def _remove_ff00(data):
data_size = len(data)
ret = []
i = 0
while i < data_size - 1:
b, bnext = struct.unpack_from('2B', data, i)
if b == 0xff and bnext == 0x00:
ret.append(data[i])
i += 2
else:
ret.append(data[i])
i += 1
ret.append(data[-1])
return ret
class JpegMarkerList:
def __init__(self):
self.__markers = []
def add(self, marker):
"""
添加 marker
:param None|JpegMarker marker:
:return:
"""
if marker is not None:
self.__markers.append(marker)
def dump(self):
for marker in self.__markers:
print(marker.__dict__)
def get_markers(self, marker_identify) -> typing.List[JpegMarker]:
ret = []
for marker in self.__markers:
if marker_identify == marker.marker():
ret.append(marker)
return ret
def get_image(self) -> typing.Union[JpegImageMarker, None]:
markers = self.get_markers(FRAME_SOS)
if len(markers) != 1:
return None
else:
return markers[0]
def get_quantization_table(self) -> typing.Union[typing.Dict[int, np.ndarray], None]:
markers = self.get_markers(FRAME_DQT)
if len(markers) == 0:
return None
quantization_table = {}
for marker in markers:
quantization_table[marker.table_id] = marker.data_matrix
return quantization_table
def get_image_info(self) -> typing.Union[JpegSof0Marker, None]:
markers = self.get_markers(FRAME_SOF0)
if len(markers) != 1:
return None
return markers[0]
def get_restart_interval(self) -> int:
markers = self.get_markers(FRAME_DRI)
if len(markers) != 1:
return 0
return markers[0].restart_interval
def get_huffman_table(self) -> typing.Union[typing.Dict[str, typing.Dict[int, HuffmanCodec]], None]:
markers = self.get_markers(FRAME_DHT)
if len(markers) == 0:
return None
huffman_table = {
'DC': {},
'AC': {},
}
for marker in markers:
codec = HuffmanCodec()
codec.build_from_bits(marker.bits_length_seq, marker.symbol_seq)
if marker.type == 0:
huffman_table['DC'][marker.table_id] = codec
else:
huffman_table['AC'][marker.table_id] = codec
return huffman_table
class JpegDecoder:
def __init__(self, data):
self.__data = data
self.__offset = 0
def _read_bytes(self, fmt='c'):
ret = struct.unpack_from(fmt, self.__data, self.__offset)
self.__offset += struct.calcsize(fmt)
return ret[0]
@staticmethod
def _is_sof_marker(marker):
return marker == FRAME_SOF0 or marker == FRAME_SOF1 or marker == FRAME_SOF2 or marker == FRAME_SOF3 \
or marker == FRAME_SOF5 or marker == FRAME_SOF6 or marker == FRAME_SOF7 or marker == FRAME_SOF8 \
or marker == FRAME_SOF9 or marker == FRAME_SOF10 or marker == FRAME_SOF11 or marker == FRAME_SOF13 \
or marker == FRAME_SOF14 or marker == FRAME_SOF15
@staticmethod
def _is_app_marker(marker):
return marker == FRAME_APP0 or marker == FRAME_APP1 or marker == FRAME_APP2 or marker == FRAME_APP3 \
or marker == FRAME_APP4 or marker == FRAME_APP5 or marker == FRAME_APP6 or marker == FRAME_APP7 \
or marker == FRAME_APP8 or marker == FRAME_APP9 or marker == FRAME_APP10 or marker == FRAME_APP11 \
or marker == FRAME_APP12 or marker == FRAME_APP13 or marker == FRAME_APP14 or marker == FRAME_APP15
def _read_marker_size(self):
size = self._read_bytes('>H')
return size
def _read_app_marker(self, marker):
marker_size = self._read_marker_size()
if marker_size < 2:
return None
if marker == FRAME_APP0:
ret = JpegApp0Marker(marker)
elif marker == FRAME_APP1:
ret = JpegApp1Marker(marker)
elif marker == FRAME_APP12:
ret = JpegApp12Marker(marker)
elif marker == FRAME_APP13:
ret = JpegApp13Marker(marker)
elif marker == FRAME_APP14:
ret = JpegApp14Marker(marker)
else:
ret = JpegMarker(marker)
ret.decode(self.__data[self.__offset:self.__offset + marker_size - 2])
self.__offset += marker_size - 2
return ret
def _read_sof_marker(self, marker):
marker_size = self._read_marker_size()
if marker_size < 2:
return None
if marker == FRAME_SOF0:
ret = JpegSof0Marker(marker)
else:
ret = JpegMarker(marker)
ret.decode(self.__data[self.__offset:self.__offset + marker_size - 2])
self.__offset += marker_size - 2
return ret
def _read_dqt_marker(self):
marker_size = self._read_marker_size()
if marker_size < 2:
return None
ret = JpegDQTMarker(FRAME_DQT)
ret.decode(self.__data[self.__offset:self.__offset + marker_size - 2])
self.__offset += marker_size - 2
return ret
def _read_dht_marker(self):
marker_size = self._read_marker_size()
if marker_size < 2:
return None
ret = JpegDhtMarker(FRAME_DHT)
ret.decode(self.__data[self.__offset:self.__offset + marker_size - 2])
self.__offset += marker_size - 2
return ret
def _read_dri_marker(self):
marker_size = self._read_marker_size()
ret = JpegDriMarker(FRAME_DRI)
ret.decode(self.__data[self.__offset:self.__offset + marker_size - 2])
self.__offset += marker_size - 2
return ret
def _read_image(self):
marker = JpegImageMarker(FRAME_SOS)
if self.__data[-2:] != b'\xff' + FRAME_EOI:
return None
marker.decode(self.__data[self.__offset:-2])
self.__offset = len(self.__data) - 2
return marker
def read_markers(self):
marker_list = JpegMarkerList()
while self.__offset < len(self.__data):
if self._read_bytes() != b'\xff':
return None
marker = self._read_bytes()
if self._is_app_marker(marker):
marker_list.add(self._read_app_marker(marker))
elif self._is_sof_marker(marker):
marker_list.add(self._read_sof_marker(marker))
elif marker == FRAME_DQT:
marker_list.add(self._read_dqt_marker())
elif marker == FRAME_DHT:
marker_list.add(self._read_dht_marker())
elif marker == FRAME_SOS:
marker_list.add(self._read_image())
elif marker == FRAME_DRI:
marker_list.add(self._read_dri_marker())
elif marker == FRAME_EOI:
return marker_list
elif marker == FRAME_SOI:
continue
else:
return None
def read_data(self):
markers = self.read_markers()
image_marker = markers.get_image()
# 仅处理YCrCb
if image_marker.channel_count != 3:
return None
# 获取 sof0,得到图片大小和各通道信息
image_info = markers.get_image_info()
# 仅处理 YCrCb
if image_info.channel_count != 3:
return None
# 获取dqt表
quantization_table = markers.get_quantization_table()
# 哈夫曼编码表
huffman_table = markers.get_huffman_table()
# 初始化之流信号 prev 表
dc_prev = {}
for channel_id in image_info.channel_info.keys():
dc_prev[channel_id] = 0
# restart interval
restart_interval = markers.get_restart_interval()
restart_interval_to_go = restart_interval
restart_count = 0
# 开始解码
image_stream = BitStream(image_marker.image_data)
img = np.zeros([image_info.width + 16, image_info.height + 16, 3], np.uint8)
for y in range(0, image_info.width, 16):
for x in range(0, image_info.height, 16):
for channel_id, channel_info in image_info.channel_info.items():
channel_huffman_map = image_marker.huffman_map[channel_id]
dc_codec = huffman_table['DC'][channel_huffman_map['DC']]
ac_codec = huffman_table['AC'][channel_huffman_map['AC']]
quantization = quantization_table[channel_info['dqt_id']]
for y_block in range(channel_info['vertical_factor']):
for x_block in range(channel_info['horizontal_factor']):
if restart_interval > 0 and restart_interval_to_go == 0:
marker = image_stream.get_bits(8)
if (marker & 0x07) != (restart_count & 0x07):
raise UserWarning('error restart marker')
restart_count += 1
restart_interval_to_go = restart_interval
for i in image_info.channel_info.keys():
dc_prev[i] = 0
idct, dc_prev[channel_id] = self.process_huffman_data_unit(image_stream,
dc_codec,
ac_codec,
quantization,
dc_prev[channel_id])
if channel_info['vertical_factor'] == 2 and channel_info['horizontal_factor'] == 2:
img[y + y_block * 8: y + (y_block + 1) * 8, x + x_block * 8: x + (x_block + 1) * 8,
channel_id - 1] = idct
elif channel_info['vertical_factor'] == 2 and channel_info['horizontal_factor'] == 1:
tmp = np.zeros([8, 16], np.uint8)
tmp[:, ::2] = idct
tmp[:, 1::2] = idct
img[y + y_block * 8: y + (y_block + 1) * 8, x: x+16, channel_id - 1] = tmp
elif channel_info['vertical_factor'] == 1 and channel_info['horizontal_factor'] == 2:
tmp = np.zeros([16, 8], np.uint8)
tmp[::2, :] = idct
tmp[1::2, :] = idct
img[y: y + 16, x + x_block * 8: x + (x_block + 1) * 8, channel_id - 1] = tmp
else:
img[y: y + 16, x: x + 16, channel_id - 1] = ndimage.interpolation.zoom(idct, 2)
restart_interval_to_go -= 1
# YCbCr 转 BGR
for y in range(0, image_info.width):
for x in range(0, image_info.height):
color_b = img[y, x, 0] + 1.772 * (img[y, x, 1] - 128)
color_g = img[y, x, 0] - 0.344136 * (img[y, x, 1] - 128) - 0.714136 * (img[y, x, 2] - 128)
color_r = img[y, x, 0] + 1.402 * (img[y, x, 2] - 128)
img[y, x, :] = [color_b, color_g, color_r]
return img[0:image_info.width, 0:image_info.height, :]
@staticmethod
def process_huffman_data_unit(image_stream: BitStream,
dc_codec: HuffmanCodec,
ac_codec: HuffmanCodec,
quantization: np.ndarray,
prev_dc_symbol: int):
dct = np.zeros([64])
# 解码直流部分
huff_symbol = dc_codec.get_symbol(image_stream)
if huff_symbol > 0:
bits = image_stream.get_bits(huff_symbol)
prev_dc_symbol += decode_number(huff_symbol, bits)
dct[0] = prev_dc_symbol
else:
dct[0] = prev_dc_symbol
# 解码交流部分
index = 1
while index < 64:
huff_symbol = ac_codec.get_symbol(image_stream)
if huff_symbol == 0:
# EOF
break
if huff_symbol > 15:
index += huff_symbol >> 4
huff_symbol &= 0x0f
dct[index] = decode_number(huff_symbol, image_stream.get_bits(huff_symbol))
index += 1
dct = dct.reshape([8, 8])
dct = inverse_zigzag_single(dct)
dct = dct * quantization
idct = fft.idct(fft.idct(dct.T, norm='ortho').T, norm='ortho')
idct = idct + 0x80
idct = idct.astype(np.uint8)
return idct, prev_dc_symbol
if __name__ == '__main__':
with open('test.jpg', 'rb') as fp:
decoder = JpegDecoder(fp.read())
img = decoder.read_data()
cv2.imshow('img', img)
cv2.waitKey(0)
cv2.destroyAllWindows()